How to unpivot pandas DataFrame (wide to long format)
The pandas melt() function helps in unpivoting the wide format DataFrame into the long format i.e. converts columns
into rows. The pandas melt() function can be used as below.
pandas.melt(df, id_vars=['col1'], value_vars=['col2', 'col3', ..., 'colN'])
Now, let’s understand the pandas melt() function with some examples.
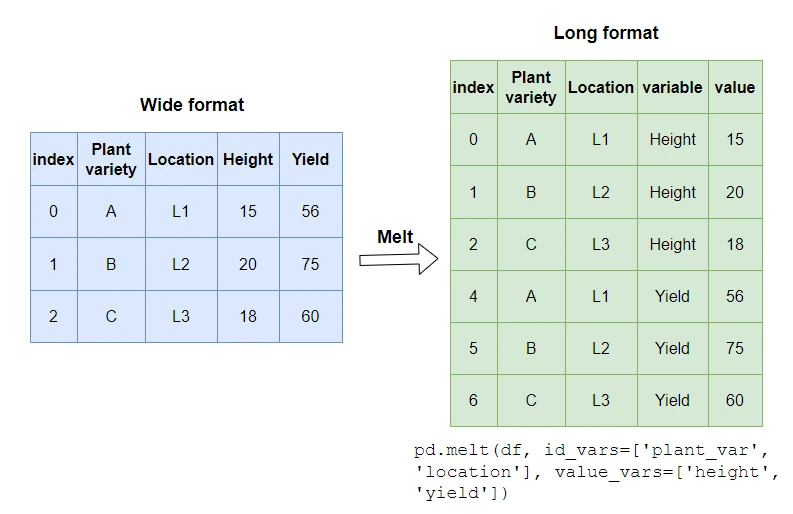
Unpivoting (melting) pandas DataFrames from wide to long format is often necessary. pandas melt() function can be used
to do this. A long format DataFrame can be useful for summarizing data and displaying data visually.
pandas
melt()function is equivalent to R’smelt()function from reshape2 package.
The following two examples shows how to use pandas melt() function.
Example 1 (for one identifier variable)
import pandas as pd
# create dataframe
df = pd.DataFrame({'plant_var':['A', 'B', 'C', 'D', 'E'],
'height':[15, 20, 18, 21, 17], 'yield':[56, 75, 60, 70, 55]})
# output
plant_var height yield
0 A 15 56
1 B 20 75
2 C 18 60
3 D 21 70
4 E 17 55
Now, convert this wide format DataFrame into a long format using pandas melt() function
import pandas as pd
pd.melt(df, id_vars=['plant_var'], value_vars=['height', 'yield'])
# output
plant_var variable value
0 A height 15
1 B height 20
2 C height 18
3 D height 21
4 E height 17
5 A yield 56
6 B yield 75
7 C yield 60
8 D yield 70
9 E yield 55
In the above example, the id_vars and value_vars represent the identifier variables and columns to unpivot,
respectively.
In the resulting long format DataFrame, value_vars will be saved in a variable column and their associated response values
will be saved in value column. You can change these column names using var_name and value_name parameters.
import pandas as pd
pd.melt(df, id_vars=['plant_var'], value_vars=['height', 'yield'],
var_name='features', value_name='response')
# output
plant_var features response
0 A height 15
1 B height 20
2 C height 18
3 D height 21
4 E height 17
5 A yield 56
6 B yield 75
7 C yield 60
8 D yield 70
9 E yield 55
Example 2 (for multiple identifier variable)
If the input DataFrame has two (or more) identifier variables (id_vars), you can convert the wide-format DataFrame
into long-format as below
import pandas as pd
# create dataframe
df = pd.DataFrame({'plant_var':['A', 'B', 'C', 'D', 'E'], 'location':['L1', 'L2', 'L3', 'L4', 'L5'],
'height':[15, 20, 18, 21, 17], 'yield':[56, 75, 60, 70, 55]})
# output
plant_var location height yield
0 A L1 15 56
1 B L2 20 75
2 C L3 18 60
3 D L4 21 70
4 E L5 17 55
Now, convert this wide format DataFrame into a long format,
import pandas as pd
pd.melt(df, id_vars=['plant_var', 'location'], value_vars=['height', 'yield'])
# output
plant_var location variable value
0 A L1 height 15
1 B L2 height 20
2 C L3 height 18
3 D L4 height 21
4 E L5 height 17
5 A L1 yield 56
6 B L2 yield 75
7 C L3 yield 60
8 D L4 yield 70
9 E L5 yield 55
By default, the melt() function reset the index. If you want to preserve the index, you should set the ignore_index
parameter to False.
import pandas as pd
pd.melt(df, id_vars=['plant_var', 'location'], value_vars=['height', 'yield'], ignore_index=False)
# output
plant_var location variable value
0 A L1 height 15
1 B L2 height 20
2 C L3 height 18
3 D L4 height 21
4 E L5 height 17
0 A L1 yield 56
1 B L2 yield 75
2 C L3 yield 60
3 D L4 yield 70
4 E L5 yield 55
You can see that index values are preserved by using the ignore_index=False parameter.
Enhance your skills with courses Python and pandas
- Mastering Data Analysis with Pandas
- Python for Data Analysis: Pandas & NumPy
- Introduction to Data Science in Python
- Python for Everybody Specialization
- Python 3 Programming Specialization
If you have any questions, comments or recommendations, please email me at reneshbe@gmail.com
This work is licensed under a Creative Commons Attribution 4.0 International License
Some of the links on this page may be affiliate links, which means we may get an affiliate commission on a valid purchase. The retailer will pay the commission at no additional cost to you.

